


It’s been over a year since we started working on the Vulkan SC Ecosystem. Now that the component stack has reached a high level of maturity, it seemed appropriate to write an article about the secret sauce behind the Vulkan SC Ecosystem components that enabled us to leverage the industry-proven Vulkan Ecosystem components to provide corresponding developer tooling for the safety-critical variant of the API.
Vulkan SC was released by the Khronos Group in 2022 as the first of the new generation of explicit APIs to target safety-critical systems. The Vulkan SC 1.0 specification is based on the Vulkan 1.2 API and aims to enable safety-critical application developers access to and detailed control of the graphics and compute capabilities of modern GPUs. In order to accomplish that, Vulkan SC removes functionality from Vulkan 1.2 that is not applicable, not relevant, or otherwise not essential for safety-critical markets, and tweaks the APIs to achieve even more deterministic and robust behavior to meet safety certification standards.
The Vulkan SC Ecosystem components, such as the ICD Loader and Validation Layers, are not safety certified software components themselves, rather, they are developer tools intended to be used by application developers writing safety-critical applications using the Vulkan SC API. Building on the success of the corresponding ecosystem components available for the Vulkan API, the goal for the Vulkan SC Ecosystem is to leverage the tremendous engineering effort that went (and still goes) into those in order to create a comparably comprehensive suite of developer tools for the safety-critical variant of the API, amended with additional features specific to Vulkan SC. Reaching that goal, however, came with its own set of challenges…
The Challenges
While the Vulkan SC API is derived from the Vulkan API, it has some significant differences in order to fulfill the special requirements of safety-critical applications including, but not limited to, the following:
- Device child objects are allocated from a static pool reserved at device creation time
- Shader compilation is handled offline using a separate vendor-specific pipeline cache compiler (PCC)
- Command pool memory is reserved up-front
- Fault callbacks are added to the API to notify the application about critical faults
- Features that are not needed (e.g. shader modules) and that are not a good fit for a safety-critical environment (e.g. sparse resources) were removed

Overall, it can be said that Vulkan SC is neither a subset, nor a superset of Vulkan, but rather an API that has a large overlap with Vulkan, and many of the API differences have a significant impact on how applications and developer tools are expected to behave. Still, due to the large overlap, it is of the utmost importance from a feasibility point of view for the Vulkan SC Ecosystem components to reuse as much of the Vulkan Ecosystem efforts as possible.
Another key part of the challenge, beyond the API and behavior differences, is that the Vulkan and Vulkan SC APIs are developed to maintain as much alignment as possible but do need to diverge to address market-specific requirements, and therefore the Vulkan SC Ecosystem components also need to exist as separate variants of the corresponding Vulkan Ecosystem components with little to no impact on the latter, while also retaining the ability to leverage ongoing general improvements made on the Vulkan side. The first prototypes of the Vulkan SC Ecosystem components, built before we joined the project, therefore were created by forking the corresponding Vulkan Ecosystem components and patching them with Vulkan SC specific changes (mostly through appropriate #ifdef VULKANSC preprocessor magic).
Unsurprisingly, as it usually happens with permanent forks, this approach turned out to be difficult to maintain, particularly for components enjoying a fast evolution such as the Validation Layers, due to the sheer number of places the upstream code needed to be patched and the unmanageable number of merge conflicts those cause during downstreaming.
The goal for us was clear: we need to find a maintainable architecture that enables us to apply Vulkan SC related modifications to the upstream components without any intrusive changes to the latter. The tricky part of achieving that is that we had to find a way to significantly modify behavior while modifying as little of the code we inherit from the Vulkan Ecosystem components in order to avoid merge conflict churn. All of this while also reusing as much of the upstream code as possible. The great thing about working in a very restrictive environment, where your hands are pretty much tied behind your back, is that it stimulates creativity.
Getting Things to Build
In order to build a new, maintainable solution for the problem at hand, we decided to start fresh and work out the details from first principles. Most of the #ifdef modifications in the original prototype implementation were needed because the Vulkan API, and thus its headers, contain some differences in the set of function and type definitions compared to Vulkan SC, primarily due to the different set of extensions supported by the two APIs. Therefore being able to compile a common code base against the latter immediately required eliminating all code that depended on Vulkan definitions that do not exist in Vulkan SC using the traditional #ifdef approach.
These headers are generated from an XML registry which is logically separate for the two APIs, but since the Vulkan SC specification regularly downstreams Vulkan specification changes, and upstreams its own definitions, they now do coexist in a single XML registry file. The definitions in this common XML registry include appropriate annotations when the effective registries of the two APIs differ (e.g. for Vulkan-only definitions, Vulkan SC-only definitions, or common definitions that are used differently in the two APIs). The header generation tooling uses these annotations to decide which definitions to include (and how) in the generated headers based on whether the target API variant is Vulkan or Vulkan SC.
To solve the compilation problem against different variants of the headers, we added a new capability to the header generation tooling that enables generating combined headers for Vulkan SC that also contain Vulkan definitions that are otherwise not available for use in Vulkan SC applications. These combined headers are not official, their sole purpose is to be used by the ecosystem components, so they are automatically generated as part of the build process.

Using these combined headers allowed us to avoid making intrusive changes to the ecosystem component code we inherited from upstream and eliminated the need for most of the #ifdefs that existed in the original prototypes, leaving us with fairly minor and manageable deviations from upstream for most components, with the notable exception of the Validation Layers where this was only the first step to reach our goal.
Generated Code
The ecosystem components contain a fair amount of code that is automatically generated using python scripts based on the XML registry, such as:
- Boilerplate code for dispatching and, in general, dealing with API entry points
- Reflection utilities to enable pretty printing the names and details of API constructs
- Utilities dealing with extensions, features, structure chains, etc.
Some components go even further. In particular, as the XML registry also contains metadata related to the expected use of various API constructs, a good chunk of actual validation code of the Validation Layers (for example, the validation of so-called implicit valid usage clauses) is also generated using such scripts.
For the most part, these just work, regardless of the target API variant, as they use the common XML registry tooling to extract the definitions corresponding to the API variant in question. However, some of the fundamental differences between the Vulkan and Vulkan SC APIs also require alternative code generation for the two based on conditions that are not expressed in the XML registry. In order to deal with these differences, the code generation python scripts have been extended with additional hooks and tools that enable modifying the code generation process depending on the target API variant. Also, as a side effect of using the combined headers, some generated code similarly needs to work based on the combined set of definitions of the two APIs (e.g. reflection utilities).
Adding Vulkan SC Validation
Building the Validation Layers for Vulkan SC is one thing, being able to maintain a fork of the Vulkan Validation Layers with Vulkan SC specific validation code added to it is another. The main challenge is to be able to add validation code specific to Vulkan SC or modify the behavior of validation code inherited from the upstream Vulkan Validation Layers without continuous maintenance burden caused by conflicting changes made in the upstream and downstream repositories.
From maintenance point of view, the key thing to get right is how the core validation (CoreChecks class) and the state tracking (ValidationStateTracker class) code is organized relative to the baseline Vulkan Validation Layers, as that is where the majority of change conflicts could happen. The Vulkan Validation Layers use an architecture based on class inheritance, where all stateful validation layers consist of state tracking and a derived validation class specific to the particular use case. We extended this by introducing additional derived classes with Vulkan SC specific state tracking and validation, as depicted below:

NOTE: The class hierarchy depicted above has been changed in the Vulkan Validation Layers since the original implementation and will continue to evolve, but the principle remains.
With this architecture, all Vulkan SC specific validation and state tracking can be maintained completely separately (in their own classes and files), which avoids the painful troubles that come with maintaining such a downstream repository.
In this architecture the validation layers will still perform all Vulkan-specific validation checks and some of them may not apply to Vulkan SC. Aside from the negligible performance cost, this does not cause any practical issues in most cases, as all those checks are typically behind corresponding API, extension, or feature checks that would simply not pass on Vulkan SC. However, there are a few exceptions where Vulkan SC deviates in some validation rules compared to Vulkan in subtle ways. These corner cases are handled by explicitly checking the Vulkan SC specific rules in the Vulkan SC specific validation code and using the built-in VUID filtering tools of the Validation Layers to ignore any validation errors that do not apply in Vulkan SC.
API Versions, Extensions, and Features
The Validation Layers contain a lot of code that checks the used API version, and the enabled extensions and features. The API version checks are already an issue from the perspective of Vulkan SC compatibility, as the uint32_t value used to represent an API version is encoded differently in Vulkan and Vulkan SC as the latter uses a non-zero API variant ID at bit offset 29. Furthermore, Vulkan SC 1.0 is more or less equivalent to Vulkan 1.2, barring the API variant specific differences. Modifying every piece of code in the Validation Layers to check for Vulkan SC API versions instead of Vulkan API versions is neither a small task nor is it going to be maintainable due to constant merge conflicts and the introduction of new version checks.
Instead, our solution to the problem was to replace the existing raw storage of the uint32_t values representing API versions with an APIVersion class that is customized for Vulkan SC to automatically understand and handle the mapping between Vulkan and Vulkan SC API versions in its comparison operators, making the existing checks of the API version against specific Vulkan API versions work as expected even when run in a Vulkan SC environment.
Similarly, handling of extensions and features promoted to a core version, including implicit promotions resulting from Vulkan SC 1.0 being based on Vulkan 1.2, are all handled transparently, without any modifications to the upstream code, thanks to some clever code generation and infrastructure.
Validation Layer Tests
Even if we solve all problems on the implementation side, we cannot be sure about the correct behavior of the Validation Layers without proper test coverage. The Vulkan Validation Layers have thousands of test cases that we need to leverage in addition to adding our own Vulkan SC specific test cases. The former is a must have, otherwise we would have to redo years of test coverage effort already developed upstream and continue to do so as the API development moves forward. The original prototype of the Vulkan SC Ecosystem did not have a solution for this, so we had to come up with one.
The tricky part is that even though the test suite would build just fine using the combined headers, executing them against a Vulkan SC implementation would not work due to the API differences. While some of these differences, like the Vulkan SC requirement to provide object reservation information at device creation time, are fairly trivial to handle at the test framework level, there are many other API and behavior differences that would normally require non-trivial and intrusive changes to the test cases in order to make them compatible with a Vulkan SC implementation. Just thinking about the fact that Vulkan SC requires the use of an offline pipeline cache compiler and the built pipeline cache data being specified at device creation time shows that we have fundamental issues that we have to solve or work around before even thinking about being able to run the validation layer tests against a Vulkan SC implementation.
We could have chosen to handle this in a similar fashion to the Vulkan SC CTS, i.e. by running the tests in a two pass process where first we capture pipeline creation parameters (including the SPIR-V shader modules), build a pipeline cache binary from those using the pipeline cache compiler, and then re-run the tests, but that approach has its own set of problems.
The more interesting question to ask ourselves first is whether it is necessary at all to run the validation layer tests against an actual Vulkan SC driver. If we think about it, the Validation Layers mostly test negative cases, i.e. when the behavior of the API is undefined because we violated some API usage rules, and even the positive tests only care about not generating validation errors when we shouldn’t. After all, we test the Validation Layers, not the Vulkan SC implementation, so it shouldn’t make a difference whether we run that against a real driver or some placeholder one. In fact, this is the approach the upstream Vulkan Validation Layers use to run the tests in Github Actions, as no real GPU hardware is available there. Instead, the tests run against the Mock ICD, which is a placeholder driver that (for the most part) does not do anything.
There is one particular exception when having a real driver in the stack is relevant: GPU-assisted validation (or GPU-AV). This new type of validation is an additional component available in the Vulkan Validation Layers that uses shader instrumentation, by patching the incoming SPIR-V shader modules, to perform fine-grained device-side validation, but it is not directly applicable to Vulkan SC, as Vulkan SC uses offline shader compilation.
Based on this, the choice was clear for Vulkan SC: we should just rely on Mock ICD based testing for the validation layer tests, because it should be sufficient to achieve full coverage. Furthermore, as we did not have to run the tests against real Vulkan SC implementations, we could also get away without any real pipeline cache data, so we could avoid the whole offline pipeline cache compilation problem.
Still, even if we deal with all of the basic API differences at the test framework level (such as additional input structures for certain APIs, differences in API version handling, promoted and available extensions and features), a lot of the test cases written for the Vulkan Validation Layers would still not run fine against the Vulkan SC Validation Layers. For example:
- The test case may not even be applicable to Vulkan SC, as it tests a Vulkan-specific validation rule that simply does not exist in Vulkan SC (e.g. unsupported feature or pre-Vulkan 1.2 rule)
- The test case may not apply to Vulkan SC because the respective validation rule has been changed in Vulkan SC compared to Vulkan
- The test case may rely on some functionality that is removed in Vulkan SC (e.g. being able to free/destroy certain object types that are not destructible in a safety-critical environment)
- The test case may depend on shader source code (SPIR-V) availability
- The test case may be relevant, but triggers an undesired Vulkan SC-specific explicit or implicit valid usage clause by chance
Simple test case filtering would have worked for most cases, but we clearly saw the need for something more powerful that enables us to mark and potentially patch individual test cases. In order to achieve that, we introduced a new (manually triggered) test case converter tool that “transpiles” the upstream test cases written for the Vulkan Validation Layers to a patched version that, among other things, allows the following control over individual test cases:
- Disable test cases that are not applicable to Vulkan SC
- Disable test cases that are replaced with Vulkan SC equivalents
- Disable test cases on specific platforms (such as QNX) due to compatibility issues
- Mark test cases that depend on SPIR-V shader module data availability
- Add custom object reservation to test cases that may use unusually large number of objects/resources
- Add additional feature (or other) dependencies to test cases that have additional prerequisites in Vulkan SC

This test converter tool (which is nothing but a fairly straightforward python script, see vksc_convert_tests.py), together with some test framework customizations, enabled us to reuse nearly all of the upstream test cases in one form or another (although, unsurprisingly, a large number of test cases remain skipped on Vulkan SC due to unsupported extension and/or feature dependencies).
This, however, isn’t the end of the story of the validation layer tests for Vulkan SC, as Vulkan SC introduced some physical device properties that have fundamental effects on the overall behavior of the API and therefore on its validation rules. That means it’s not enough to make sure that we add additional tests for all additional Vulkan SC specific validation rules, we need a runtime environment where we can test against “devices” with or without support for specific physical device capabilities/attributes.
As a result, we needed a way to simulate different device properties in order to achieve full coverage. Fortunately, this is not an entirely new problem. Vulkan already has a tool that allows achieving exactly that: the Vulkan Profiles Layer. This layer can take a JSON profile file describing a set of device capabilities and report those to an application instead of the actual device capabilities. We created an analogous component for Vulkan SC called the Vulkan SC Device Simulation Layer which we use to test the validation layer tests with different device capability sets. This approach has also been adopted upstream in the meantime so the Vulkan Validation Layers are also tested now using the Vulkan Profiles Layer with different device profiles.

It is important to note that there is nothing specific to our testing needs in the Vulkan SC Device Simulation Layer. That means application developers can use it in a similar fashion to test their Vulkan SC applications against different device capabilities as they would use the Vulkan Profiles Layer in case of Vulkan applications.
SPIR-V Dependent Validation
We’ve already alluded to the fact that, some validation rules depend on the availability of SPIR-V shader module data (just think about all the rules that cross-validate shader code against API state). Support for these SPIR-V dependent validation rules is one of the more recent additions to the Vulkan SC Validation Layers.
Of course, the key to that is that we actually need to have SPIR-V shader module data available in the Validation Layers in order to be able to validate the corresponding rules. This is not the case by default, as the pipeline cache data produced by the offline pipeline cache compilers usually contain only the final vendor-specific ISA (and any other implementation-specific state related to the pipelines). However, these offline pipeline cache compilers typically also allow embedding debug information into the generated pipeline cache data. This debug information includes the JSON description of the pipeline, as well as the SPIR-V binaries of the individual shader stages.
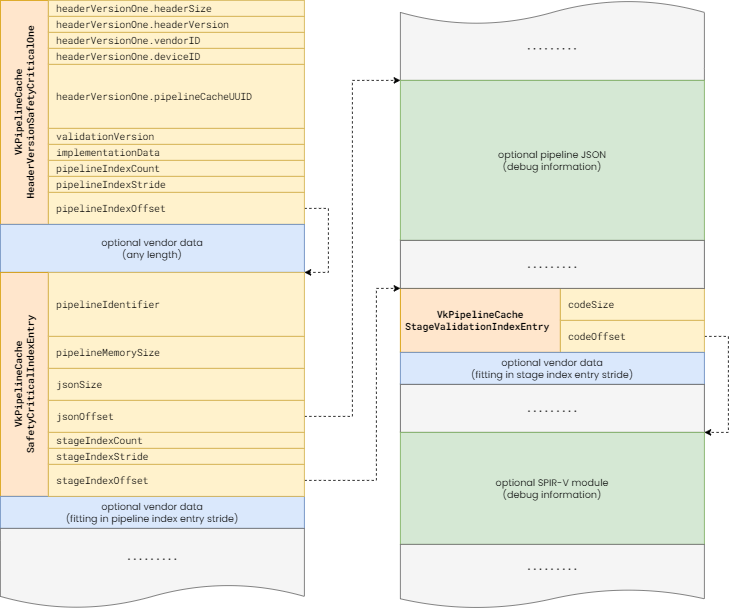
As the Vulkan SC pipeline caches have a well-defined internal representation (aside from the implementation-specific data), as depicted above, the Vulkan SC Validation Layers are able to parse these, when available, and use them during validation, enabling the same level of SPIR-V dependent validation as in Vulkan. Just make sure you configure your offline pipeline cache compiler to emit the debug information.
With this feature included, the testing vector also had to change as we needed to make sure that the Vulkan SC Validation Layers operate correctly both with and without SPIR-V debug information. That was fairly straightforward to accomplish thanks to the test converter tool which we could use to mark test cases that depend on SPIR-V debug information to make sure they are only executed when SPIR-V debug information is actually available.
There is one more trick we applied in the test framework to be able to run the upstream SPIR-V dependent test cases against the Vulkan SC Validation Layers. The upstream test cases were written for Vulkan, therefore they use shader modules and on-demand pipeline creation. In order to translate these into Vulkan SC API calls, we had to create internal container objects for the shader modules, and create pipeline caches built from those, on demand.
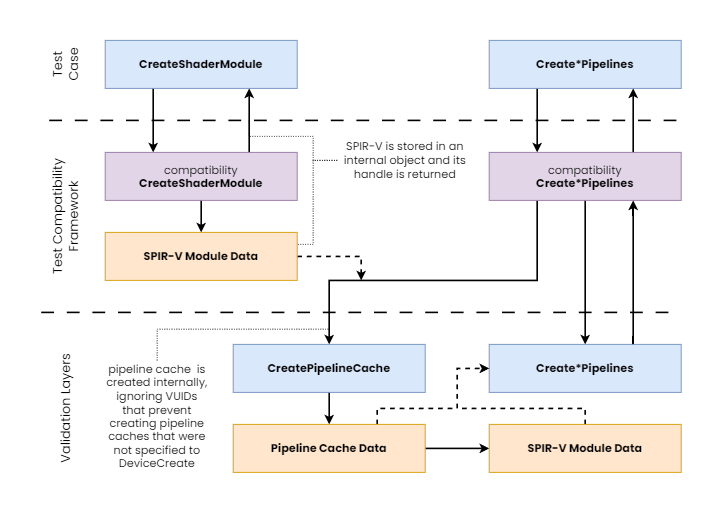
As shown in the diagram above, this required us to ignore valid usage clauses disallowing the creation of pipeline caches with pipeline cache data that was not specified at the time the device was created. However, we can safely do that here, because we are only testing with the Mock ICD, and the tests are not supposed to work on a real Vulkan SC driver implementation. After all, we are testing the Vulkan SC Validation Layers here, not drivers, and this trick allowed us to further increase our test coverage without having to replicate hundreds of existing upstream test cases downstream.
Summary
The Vulkan SC Ecosystem has come a long way since the first prototypes released in 2022. The Vulkan SC Validation Layers, in particular, transformed from a limited functionality prototype into a fully featured and thoroughly tested component that is ready for prime time use. Most importantly, we now have a set of efficiently maintainable ecosystem components that can be extended with additional Vulkan SC specific capabilities while also leveraging all the upstream efforts going into the Vulkan Ecosystem.
You can find the individual ecosystem components in the following repositories:
- VulkanSC-Headers – official API headers and combined header generation tooling
- VulkanSC-Utility-Libraries – utilities used by the ecosystem components that are also available for application use
- VulkanSC-Loader – ICD loader
- VulkanSC-Tools –
vulkanscinfocommand line tool, the mock ICD, and the device simulation layer - VulkanSC-ValidationLayers – validation layers
We are very proud that the Vulkan SC Working Group trusted us with taking on this project and giving us the opportunity to rebuild the Vulkan SC Ecosystem on a new, solid foundation, and we’re looking forward to sharing more news about the ongoing evolution of the Vulkan SC Ecosystem in the future.