


Today’s high computational throughput probably would not be attainable without the application of the SIMD paradigm in modern processors in increasingly clever ways. It’s no coincidence that GPUs also gain most of their performance, die area, and efficiency benefits thanks to this instruction issue scheme. In this article we will explore a couple of examples of how GPUs may take advantage of SIMD and the implications of those on the programming model.
Before proceeding, it’s worth noting that we will not discuss processor hardware design, thus we will not dwelve into details of individual components within a processor core, superscalar processor architecture, issue ports, instruction-level parallelism, register files, bank conflicts, etc. Our focus will be on aspects of the various uses of the SIMD paradigm that have a direct effect on the way developers should write efficient code for such processors, and will only touch marginally on subjects beyond that. That is not to say those hardware details and many other nuances of a specific target architecture have no significant impact on the way code should be written for such devices in order to achieve optimal performance, however, such a discussion is well beyond the scope of this article.
What is SIMD?
The term comes from Flynn’s classification of computer architectures. SIMD stands for single instruction, multiple data, as opposed to SISD, i.e. single instruction, single data corresponding to the traditional von Neumann architecture. It is a parallel processing technique exploiting data-level parallelism by performing a single operation across multiple data elements simultaneously.

Looking at it from a different perspective, SIMD enables reusing a single instruction scheduler across multiple processing units. That allows processor designers to save significant die area and hence achieve greater computational throughput with the same number of transistors compared to traditional scalar processing cores having a one-to-one mapping between instruction schedulers and processing units.
The SIMD model is not unique to massively parallel processors like GPUs, in fact CPUs have a long history of employing SIMD instruction sets like MMX, SSE, NEON, and AVX that can be used in addition to the traditional scalar operations provided by the CPU. While our focus will be on GPUs, we will also see a couple of examples of those.
Vector SIMD
Traditionally, 3D graphics workloads were all about vector operations and to some extent they still are:
- Rendering 3D scenes require certain linear transformations of geometric attributes like position, normal, and texture coordinates which involves vector-matrix multiplications which themselves comprise of multiple vector-vector operations (dot products) often performed on 4-component vectors representing homogeneous coordinates
- Determining the color of individual vertices and/or pixels usually involves complex lighting calculations which themselves usually comprise of 3- or 4-component vector operations where the vectors represent colors (in RGB or RGBA format) or directions like the surface normal, incoming light direction, reflection direction, etc.
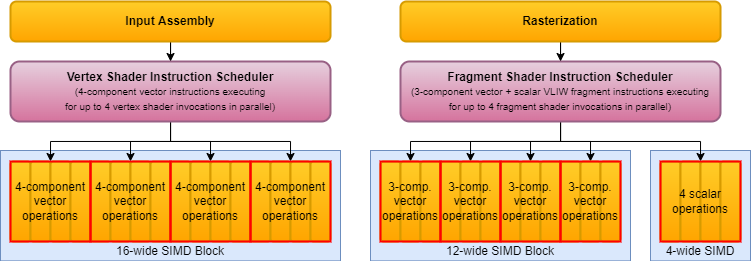
It is thus no surprise that GPUs used SIMD units since the early days to implement vector instructions. It is also not a coincidence that the first programmable shaders used assembly-like shading languages providing instructions operating on 4-component vectors.
The atomic unit of data in this model is a 4-component vector with floating point components. Assuming standard IEEE 754 32-bit floating point values, we get vector registers with a total width of 128 bits. This form of SIMD operating on registers with multiple components is hence often also referred to as packed-SIMD, or SWAR (SIMD within a register).
There are two instructions (or family of instructions) that are worth calling out in particular.
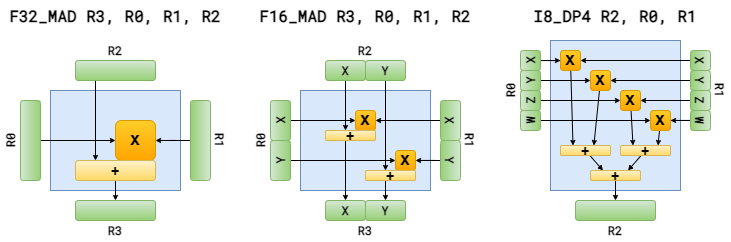
The first is MAD (multiply-add) or MAC (multiply-accumulate) which is available on practically all GPUs as a single instruction, as graphics and multimedia workloads are full of scale-and-bias operations. This means that on traditional 4-component vector based GPUs it takes only a single instruction to calculate 4 floating point multiplications and 4 additions, and floating point MAD/MAC is still often used as the unit for measuring the instruction throughput of GPUs.
The second is the various flavours of dot product instructions (e.g. DP4 or DP3) that calculate the scalar (or dot) product of two vectors. These themselves, more or less, comprise of MAD/MAC operations, hence they are similarly “cheap” operations to perform on a vector SIMD processor. As most of the transformation and lighting calculations directly or indirectly comprise of dot products, vector SIMD processors greatly benefit of single-instruction dot products both from throughput and latency perspective.

As processing time is dominated by the multiplications, both operations can be completed with comparable latency. Also note that the scalar result of the DP4 instruction is usually replicated across the channels of the destination vector register, by default (unless requested otherwise as we’ll see later).
CPU SIMD instruction sets also use packed-SIMD technology. As an example, on x86 the SSE instruction set also enables performing operations across multiple data elements in a single instruction by interpreting the XMM registers as packed vectors with multiple components.
When it comes to vector SIMD processors, it’s worth noting two key techniques popularized by them:
- Component swizzling – the ability to redirect individual components of source operands to individual processing units, and similarly redirect individual output components to destination components
- Component masking – the ability to discard individual output components (or, analogously, disable individual processing units)
These enabled expressing more complex variations of the same operation by reducing the number of components to process, replicating an input or output across components, etc. Implementations typically also support special constant swizzles where the corresponding component of the operand is replaced with one of the commonly used constant values like 0.0, 1.0, 2.0, and 0.5 (potentially even more). Making all (or at least most) instructions accept custom swizzling and masking can significantly reduce the number of instructions for a given workload as it eliminates the need for most move instructions.

Note that in the example on the right the 3rd (Z) component of the output is masked but in effect it’s the 4th channel in the SIMD that is unused. The latter is really arbitrary and in fact different SIMD instruction sets use different ways to express masking (as we will see later).
While traditional vector-based GPUs are less prevalent nowadays, packed-SIMD technology is still in use in other forms, as we will see later.
From Vector to Scalar
As GPU workloads evolved, more and more scalar operations creeped their way in the shaders making it increasingly more difficult to reach the theoretical computational throughput of traditional vector-based GPUs. As these processors were vector-oriented by design, performing scalar operations usually meant the execution of a vector instruction with all but one component masked out.
While sometimes it’s possible to combine multiple scalar operations into a single vector instruction, e.g. four independent scalar additions can be trivially merged into a single vector addition and thus utilizing all processing units, it is usually difficult to find enough independent scalar operations of the same kind. Nonetheless, when targeting vector-based GPUs or other packed-SIMD instruction sets, generally it’s highly advised to try to vectorize calculations as the application developer can often do a better job at that than even an optimizing compiler.
Some GPU architectures thus moved from a traditional vector-based architecture to a VLIW one. VLIW stands for very long instruction word, and processors using such an instruction set utilize complex instructions which comprise of multiple operations that are executed in parallel.
Some VLIW based GPUs used a 3+1 structure where a single instruction encoded one operation to perform on the first three components of the vector register, and another to perform on the fourth component, acknowledging the fact that RGBA values often required separate operations to be performed on the RGB color channels compared to the alpha channel, and that for many calculations 3-component vector operations were sufficient (color-only, direction vector, or affine transformation operations) leaving the fourth processing unit available to execute e.g. a completely independent scalar operation.

Transcendental operations (e.g. trigonometric and logarithmic operations) and other non-trivial operations (division, square root, etc.) typically only used with scalar operands were often implemented only on the fourth processing unit, often called the transcendental unit, aligning the processor design better to the expected workload while saving precious die area.
Over time more and more complex VLIW based GPUs appeared with various widths and ever more flexible ways to specify multiple operations within a single instruction. In their most sophisticated incarnations the VLIW instruction sets allow scheduling practically any operation separately for each component.
VLIW based GPUs, hence, have an edge over traditional vector-based ones in that almost any set of operations can be merged into a single VLIW instruction covering the entire width of the processing block, as the operation itself can vary per component (or groups of components) in each instruction, not just the data.
However, those operations generally still have to be independent, i.e. no source of either operation may depend on the result of another within a single instruction, hence despite the best optimization efforts from the application developer and the compiler, it may still result in multiple processing units idling from time to time over the course of a shader invocation’s execution due to the data dependencies.
In addition, unless the particular instruction set supports addressing different registers as source or destination operands across the different operations within a VLIW instruction, additional move operations may be necessary to comply with the operand reference limitations, just like in case of traditional vector-based GPUs.
Nonetheless, one appeal of such architectures is that they can sort of operate in a mixed mode where vector and scalar operations can be both expressed in a single instruction thus even inter-component vector math like dot products and cross products may be performed using a single instruction (although the actual time an instruction completes may vary on the operations used).
Still, the heterogeneous instruction set of such processors means that the instruction decoder and scheduler is likely to be similarly complicated thus limiting the die area benefits of using a single instruction scheduler across multiple processing units.
One way to alleviate this complexity is to use a simple scalar instruction set instead which is what AMD did, for example, with the introduction of the GCN instruction set architecture, that is likely the most well-known GPU ISA in the developer community to date. Of course, this also comes with some sacrifices, as in a completely scalar instruction set even a basic dot product requires multiple MAD/MAC instructions (although, once again, we ignore important details here, like how long each instruction actually takes to complete).
Throughout this paradigm shift it became gradually more important for application developers to use scalar operations in their shaders whenever possible and only keep vector math where that’s the natural granularity of computation.
But does all this mean we’re done with SIMD? Of course not, in fact we are just getting started…
SIMT
Vector processing is just one way to leverage the benefits of the SIMD paradigm. Another common way to utilize SIMD instructions, as it’s often done even on the CPU, is to perform array processing (contrarily to vector processing), as demonstrated in the example below:
// SISD code to perform element-wise multiplication of two arrays
void array_mul_sisd(float* C, float* A, float* B, size_t size)
{
for (size_t i = 0; i < size; ++i)
C[i] = A[i] * B[i];
}
// Same algorithm using 128-bit (4-wide) SIMD array processing (x86 SSE)
// (for simplicity, we assume the alignment and size of the arrays is appropriate)
#define FLT4(X) *((__m128*)(&(X)))
void array_mul_simd4(float* C, float* A, float* B, size_t size)
{
for (size_t i = 0; i < size; i += 4)
FLT4(C[i]) = _mm_mul_ps(FLT4(A[i]), FLT4(B[i]));
}
As it can be seen above, even though the individual work that needs to be performed on the array elements is scalar by nature, SIMD instructions can be used to process multiple array elements in parallel. This subtype of the SIMD paradigm is often called SIMT, i.e. single instruction, multiple threads. It is a misnomer, to some extent, as the “threads” we talk about here are not the independently schedulable threads of execution that we all know, but rather the threads we know from NVIDIA’s CUDA API, i.e. the individual lanes of a wave. But let’s not get ahead of ourselves…
This is really just the other side of the same coin, as we can call the above example as vectorization as well, if we really want to. However, when this vectorization isn’t explicit, but rather an artifact of the programming model then the distinction between array vs vector processing becomes clear-cut.
So far we only talked about leveraging internal parallelism within a single shader invocation, utilizing the fact that many shader computations operate on vectors of various widths and even scalar operations are ofttimes independent from each other. However, the massive parallelism of GPU workloads actually stems from having to execute the same shader code across a large number of data elements (vertices, primitives, fragments, etc.).
Thus, ignoring control flow for now, which is anyway something that wasn’t available on early programmable GPUs, it is trivial to process multiple shader invocations in parallel by scaling up the width of the SIMD unit. Of course, there are practical and technological limits to how wide it’s possible or worth to make a SIMD unit, but in theory it could go as wide as the entire processor. This allows reusing a single instruction scheduler across even more processing units than in a basic vector or VLIW processor.
Going back to our GPUs with scalar instruction sets, now it’s trivial to see that the scalar nature of the instructions themselves does not prevent us from utilizing SIMD technology, as just as their vector-based or VLIW based counterparts, the instruction stream can be issued across multiple shader invocations simultaneously, or, loosely speaking, executed in lock-step.
In practice, modern GPUs usually comprise of multiple sets of such SIMD processing blocks hierarchically aggregated into clusters sharing different types of caches and auxiliary hardware blocks performing fixed-function operations of the graphics pipeline.
In this model shader invocations that are scheduled simultaneously across the processing units of one of more SIMD blocks form a subgroup often also called a wave, wavefront, or warp, while the individual shader invocations within those are referred to as the lanes or threads of the wave.
Taking AMD’s GCN architecture as an example, while the instructions are scalar from the perspective of a single shader invocation, the instruction actually refers to these as vector instructions, as practically they perform operations of entire waves as wide vector operations where each component belongs to a particular shader invocation. Thus the scalar nature of the instruction set should not be confused with the scalar unit available on GCN GPUs (or in some recent NVIDIA GPUs) which actually behaves more as a SISD execution unit shared across the entire wave.
SIMD Control Flow
Over time GPUs gained more and more sophisticated support for shader control flow. However, in case of a SIMD unit that may process multiple shader invocations (or threads, if we must) it is less intuitive how control flow can be implemented. This is where another SIMD paradigm comes handy that is called an associative processor in Flynn’s taxonomy.
The technique expands on the idea we already covered to some extent in our discussion about vector-based GPUs whereas individual components of the vector operation could be masked out. There is no reason why we couldn’t apply the same principle for SIMD units that process multiple shader invocations in parallel.
Early incarnations of GPU control flow support did not have true branching support in the processor, more specifically, there were no jump instructions or anything similar available. Thus loops of any sort would get unrolled by the compiler and the shader authors had to be wary of the instruction limit of the target GPU as at this point instructions were not streamed from memory but were stored in a limited size on-chip buffer. Support for conditionals, however, arrived fairly early in the form of predicated/conditional instructions.
In a naive implementation this means that in case of an if-else block the GPU would execute both branches and then a conditional instruction (e.g. some form of CMOV) would select the results of the appropriate branch based on the value of the condition. This technique enables to continue utilizing SIMD technology to execute multiple shader invocations in parallel while still allowing for the individual invocations to virtually take different branches across the control flow.
// GLSL-style high-level pseudo-code
...
if (!inShadow) {
light = max(0.0, dot(L, N));
color *= light;
}
...
// Corresponding hypothetical instructions ... DP3 R1.x, L.xyz, N.xyz; MAX R1.x, R1.x, R0.0; MUL R1.xyz, COL.xyz, R1.xxx; CMOV COL.xyz, COL.xyz, R1.xyz, SHD.x; ...
Obviously, this comes at a hefty cost as all branches within the shader actually need to be executed for all shader invocations, and it’s the origin of the old advice of avoiding conditionals in shaders whenever possible that far outlived the actual GPUs without true branching capabilities. Nonetheless, even in these times, the cost of control flow was still acceptable when the computation in the actual branches was fairly limited, as in the example above.
One drawback of using the naive approach above is that we are not only paying the performance cost of both branches, but also their power cost, as all shader invocations across the SIMD unit perform both sets of calculations even though each will only use the results of one of them in the end. Thus, in practice, GPUs support predicating of pretty much every instruction through some special register(s) similar to the mask registers used by CPU instruction sets like AVX-512. Hence even the early assembly-like shading languages used such an approach and thus allowed to at least save the power cost for shader invocations not taking a particular branch.
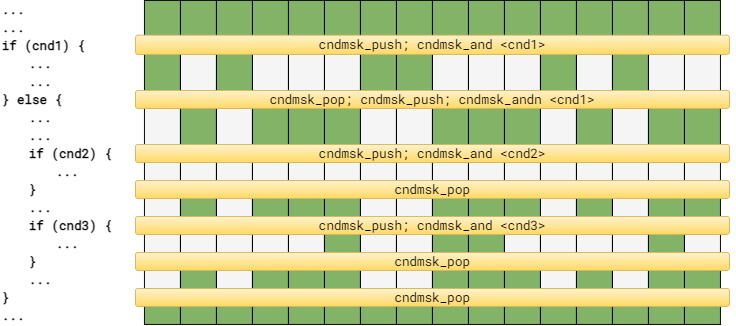
Lanes in green are active while grayed out lanes are masked out by the corresponding conditions.
Note that this is an implementation using a stack to handle nested conditionals. Stackless implementations, flattening nested conditionals is often possible with other trade-offs. More commonly, as the nesting depth is typically known for shaders, a fixed number of backup registers can be used as the stack.
Without support for branching instructions it is not possible to skip over a branch even if none of the shader invocations in the wave would take it, as it can be seen in the case of the branch on cnd2 above.
Newer GPUs then introduced actual branching instructions (jump-like or structured) that work in a similar fashion to their SISD versions. However, we must not forget that GPUs schedule and execute entire waves of shader invocations in lock-step, thus skipping over code using branching instructions is only possible if all shader invocations within the wave take the same path.
When that’s not the case we are talking about divergent waves and in such cases GPUs continue to operate like their predecessors by executing both branches of an if-else block, or worse, in case of loops it means that each shader invocation within the wave will take as many iterations as the one that takes the most. Hence, even though control flow is inexpensive on today’s GPUs, dynamically uniform control flow (as opposed to divergent) is still strongly preferred to avoid having to pay the cost of executing the instructions of multiple, shader-invocation-wise, mutually exclusive branches.

Lanes in green are active while grayed out lanes are masked out by the corresponding conditions.
Note the following:
cnd1 is a compile-time known uniform expression, i.e. it’s known from the shader code that the condition will not vary across lanes of a wave, hence only branching instructions are needed.
cnd2 is a dynamically uniform expression, i.e. it happens to be that all lanes of the wave evaluated it to the same value, hence the wave could skip the untaken branch. However, condition mask code was still necessary to be added by the compiler as dynamic uniformity is not known at compile-time.
cnd3 is a divergent expression, hence the wave will execute both sides of the branch with the appropriate predication.
If the shading language syntax allows expressing it, generation of branching code for known divergent branches, or predication code for known dynamically uniform branches can be avoided.
Cross-Lane Operations
Analogously to how the idea of component masking expands to the SIMT model in the form of instruction predication, component swizzling also has its corresponding counterpart in the form of cross-lane operations. This time instead of swizzling the components of a vector when using them as instruction operands on a vector-based GPU, data is swizzled across the shader invocations within a wave.
This technique is beneath one of the hottest shading language features in the last couple of years as it enables significantly higher performance data sharing across shader invocations within a subgroup compared to the wider (workgroup) scope but slower data exchange through shared memory, as cross-lane operations allow shader invocations to directly reference data in the registers of other shader invocations within the wave. Implementing this seems fairly trivial, considering that the registers of all shader invocations executing on a particular SIMD unit are located in the same register file.
There’s More!
Processors often employ another method to increase instruction-level parallelism without actually increasing the width of the underlying SIMD block. In this scheme the instruction scheduler issues each instruction multiple times but for different sets of shader invocations and it’s often referred to as temporal SIMT, or, when using wide SIMD blocks, spatio-temporal SIMT, as instruction issue is spread both in the spatial domain (over individual lanes of a SIMD block) and the temoral domain due to the multi-cycle reissue.
Loosely speaking, this is similar to string operations using the REP prefix on an x86 CPU, although that is far from an accurate analogy. In practice, temporal SIMT on GPUs is often a bit more rigid than that, as generally instructions are reissued a hardwired number of times. As an example, AMD’s GCN architecture issues an instruction across a complete 64-wide wave of shader invocations to a 16-wide SIMD block over 4 cycles, 16 lanes each cycle. This instruction issue technique enables the possibility to hide the latency of instruction decoding and/or execution and thus provide greater instruction-level parallelism.
Note, however, that this technique should not be confused with the simultaneous multithreading (SMT) technology often used by GPUs whereas the processor schedules instructions of other waves while a wave waits for a long-latency operation like a memory read.
Temporal SIMT can be also implemented in its pure form, i.e. without an actual wide execution unit. In this case each shader invocation within a wave is issued in separate cycles which may even enable the scheduler to skip issuing the instructions of inactive shader invocations (due to predication). Such an approach could potentially eliminate the cost of divergent shader invocations, but only up to a certain extent, as it also limits the chance of hiding operation execution latency, hence also limiting effective instruction-level parallelism, and the overall time to complete the execution of a wave would increase due to removing one dimension of parallelism.
Yet another technique is to share a single instruction scheduler across multiple SIMD blocks. While this may not be self-evident, there’s a difference between issuing instructions to multiple SIMD blocks compared to a single, wider SIMD block. For example, separate SIMD blocks have separate register files, hence simple cross-lane operations cannot be used to share data across shader invocations running on separate SIMD blocks, even if they are both fed by the same instruction scheduler.
Combining temporal SIMT with a single instruction scheduler feeding multiple SIMD blocks allows a single scheduler to handle an even larger number of instructions executing in parallel. However, sometimes this may also imply that the issue granularity may be higher than the size of a single wave. On AMD’s GCN architecture, for example, this is not the case, as a single instruction of a 64-wide wave takes 4 cycles to start on a single 16-wide SIMD block and, while there are four SIMD blocks per scheduler, the scheduler can actually issue an instruction from a separate wave each cycle, hence able to send a new instruction to all four SIMD blocks across those 4 cycles until it has to go back to the first one.
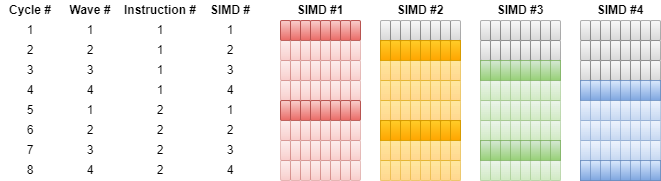
The dark colored blocks indicate the first instruction issue instances (covering the first 8 shader invocations within the wave), while the light colored blocks indicate the reissue of the same instruction for the subsequent groups of shader invocations within the same wave.
While it may have seemed that some of the techniques presented that take advantage of the SIMD paradigm are mutually exclusive, all of them can be combined. As an example, there’s no reason why a vector-based or VLIW GPU could not take advantage of the SIMT model, in fact they do, as going e.g. 4-wide with SIMD wouldn’t be sufficient to achieve the scales of computational throughput that we have seen on GPUs over the last couple of decades.
Another example of a multi-paradigm use of SIMD processing can be noted in certain SIMT based GPUs that also support multiple operand precisions (e.g. both 16-bit and 32-bit floating point operands) as this may mean that even a GPU that otherwise uses a scalar instruction set may implement lower-precision operations following the packed-SIMD paradigm, or use wider vector widths for lower-precision operations, as the register width is typically fixed by the architecture.
Conclusion
As we saw, GPUs can leverage the benefits of the SIMD paradigm in many interesting ways. All of those techniques, however, have various levels of effects on the way code should be written for them in order to maximize performance. Hence it’s important for developers to familiarize themselves with them. Fortunately, there is a high degree of commonality across the way how the various types of beasts prefer to be fed, so all is not lost. Nonetheless, there is always some extra performance to be found when targeting a particular hardware architecture.
It is also worth noting that, to some extent, the instruction set can be fairly orthogonal to the actual way the processor schedules individual operations for execution, let alone the actual execution itself. We presented a very simplistic view of how hardware may execute operations in a SIMD fashion. Modern superscalar processors with deep instruction pipelines are far more complex than that.
Also, the instruction set and the way how platform-independent shader code is mapped to it is generally hidden behind the compiler infrastructure provided by the hardware vendors. Hence sometimes one may come to incorrect conclusions about how a particular target hardware should be coded for simply based on some limited high-level information about the architecture.
Considering the shader programming model offered by the various graphics and compute APIs, it seems that at least the SIMT execution model is common across all GPU architectures on the market today (unsurprisingly), while other design choices like using a vector-based, VLIW, or scalar instruction set (or a combination of those) varies more across individual implementations.
In fact, it may not be uncommon for modern GPUs to be able to switch between various issue models (e.g. vector vs scalar, or different wave widths as we see on some recent architectures). It is thus possible that only the level of flexibility and granularity at which these issue models can be switched is what defines each unique architecture.
If GPU architectures would go in such a multi-paradigm direction then that would likely be good news for application developers, as it may allow reaching closer to optimal performance and efficiency for a wider range of algorithms.
For further reading and architecture examples, please check out the links below:
- ATI Radeon HD 2000 programming guide
- AMD Accelerated Parallel Processing – OpenCL Programming Guide
- The AMD GCN Architecture – A Crash Course
- AMD GCN Architecture Whitepaper
- AMD GCN Gen1 Instruction Set Architecture
- AMD GCN Gen2 Instruction Set Architecture
- AMD GCN Gen3 Instruction Set Architecture
- AMD Vega Instruction Set Architecture
- AMD RDNA Architecture Whitepaper
- AMD RDNA 1 Instruction Set Architecture
- AMD RDNA 2 Instruction Set Architecture
- NVIDIA Kepler Architecture Whitepaper
- NVIDIA Maxwell Architecture Whitepaper
- NVIDIA Pascal Architecture Whitepaper
- NVIDIA Volta Architecture Whitepaper
- NVIDIA Turing Architecture Whitepaper
- NVIDIA Ampere Architecture Whitepaper