


The behavior of the graphics pipeline is practically standard across platforms and APIs, yet GPU vendors come up with unique solutions to accelerate it, the two major architecture types being tile-based and immediate-mode rendering GPUs. In this article we explore how they work, present their strengths/weaknesses, and discuss some of the implications the underlying GPU architecture may have on the efficiency of certain rendering algorithms.
Let’s start with the basics first by taking a look at the way how the two major GPU architecture types implement the graphics pipeline stages.
Immediate-Mode Rendering
We can really call this GPU architecture the “traditional” one, as immediate-mode rendering (IMR) GPUs implement the logical graphics pipeline, as described by the various graphics APIs, quite literally:

- Incoming draws trigger the generation of geometry workload with a corresponding set of vertices to be processed (with appropriate primitive connectivity information according to the primitive type)
- Vertices/primitives are then fed to the various geometry processing stages (vertex shading and any other additional processing stages like tessellation or geometry shading, if enabled, or mesh shading in latest achitectures)
- The resulting primitives are then culled (and potentially clipped), transformed to framebuffer space, and sent to the rasterizer
- Fragments generated by the rasterizer then go through the various per-fragment operations and fragment processing (potentially discarded by the fragment shader)
- Finally the remaining fragment’s color values get written to the corresponding color attachments (potentially in non-trivial ways in case of multisampling, as an example)
The important takeaway is that entire draw commands are processed to completion on the GPU in a single pass and all resources are accessed through traditional (cache assisted) memory transactions.
One prerequisite of this is the existence of some sort of buffer between the front-end stages (ending with primitive assembly) and back-end stages (starting with rasterization) to be able to handle the non-uniform ratio between geometry and fragment workload that is inherent from the fact that a single incoming primitive may cover an arbitrarily large area in framebuffer space. This remains an active area of research for immediate-mode rendering architectures despite the fact that actual programmable shader processing happens across a group of unified shader cores in modern GPUs, enabling almost any form of distribution of geometry and fragment processing workloads across them.
Tile-Based Rendering
As the name suggests, tile-based rendering (TBR) GPUs execute the graphics pipeline on a per-tile basis. What this means is that the framebuffer space (also referred to as the render area) is split into equisized rectangular areas called tiles, and rasterization, as well as all other back-end stages, are executed separately for each individual tile after the front-end stages completed.
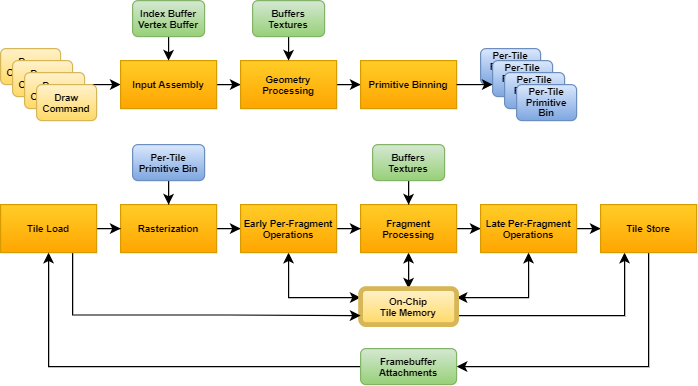
The traditional primitive assembly stage is replaced with a primitive binning stage whereas culled primitives are accumulated into one or more bins, depending on which tile within the render area do they overlap with. After the front-end stages complete, a separate per-tile pipeline is launched that:
- Starts with the tile load operation responsible to load framebuffer attachment data corresponding to the tile into dedicated on-chip storage
- Then primitives in the bin corresponding to the tile are rasterized and go through the usual per-fragment operation and fragment processing stages, but when those need to read/write framebuffer data they access the on-chip storage instead of the in-memory attachment resources
- Finally the tile store operation is responsible to store back any modified framebuffer attachment data from the on-chip storage to memory
It can be seen that the key difference between a TBR and an IMR GPU is the way they communicate primitive data between the front-end and back-end stages and the way they access framebuffer data. These dissimilarities have profound implications though, as explained later.
Algorithm Comparison
The pseudo codes below present the algorithmic differences between the IMR and TBR architectures:
# IMMEDIATE-MODE RENDERING ALGORITHM
# Single phase:
for framebuffer/subpass in pass:
for draw in subpass:
for primitive in draw:
process(primitive/vertices)
rasterize(primitive)
for fragment in primitive:
process(fragment)
# TILE-BASED RENDERING ALGORITHM
# Phase 1:
for framebuffer/subpass in pass:
for draw in subpass:
for primitive in draw:
process(primitive/vertices)
bin(primitive)
# Phase 2:
for tile in renderarea:
for framebuffer/subpass in pass:
load(framebuffer tile)
for primitive in bin:
rasterize(primitive)
for fragment in primitive:
process(fragment)
store(framebuffer tile)
For those familiar with compute shaders or other GPU compute APIs, a reasonable analogy to the behavior of TBR GPUs would be to imagine implementing the two phases of the TBR algorithm with two compute shader dispatches.
The first compute shader is ran across the domain of primitives within the whole render pass, each invocation processing a primitive and its vertices, and then appending it to the end of the per-tile buffers for each tile the primitive overlaps.
The second compute shader is ran across the domain of pixels within the render area, each workgroup covering a single tile. Invocations of the workgroup go through the list of framebuffers/subpasses and perform the following operations:
- Load the pixel corresponding to the invocation from each framebuffer attachment into shared memory
- Go through the primitives from the bin of the current subpass and determine whether the pixel corresponding to the invocation is inside the primitive, if yes, perform the appropriate per-fragment operations and fragment processing, utilizing the framebuffer data loaded in shared memory when needed
- Store the pixel data in shared memory corresponding to the invocation back into the corresponding framebuffer attachment
Of course, this is an oversimplified example on how compute shaders could mimic the behavior of TBR GPUs, and, while reasonably efficient, such a software based approach would still be significantly slower than hardware implementations, as the latter has dedicated hardware for specific fixed-function parts of the process (e.g. rasterization). Nonetheless, the analogy is surprisingly accurate if we consider that the on-chip tile memory used by TBR GPUs is fair to be expected to be backed by the same physical on-chip memory that is used to implement compute shared memory.
One question that always pops up in the context of tile-based rendering is that “okay, okay, tile-based, but what tile sizes are used?”, and while there’s usually no uniform answer even in case of a single vendor, sometimes even for a single ASIC, the general figure is that TBR GPUs typically use very small tiles, e.g. 16×16 or 32×32. Implementations may even choose the tile size dynamically, depending on the pixel size of the framebuffer attachments used within a subpass, or across a series of subpasses. This is not surprising if we examine that the tile size and the total per-pixel size of all framebuffer attachments that need to be accessed by a given subpass (or preserved for later subpasses) is what determines the total on-chip tile memory required.
So Which Architecture Is Better?
It’s quite easy to find articles and discussions on the internet making bold claims about one architecture being better than the other, or being the future. In reality, the question itself is moot, as both architectures make specific trade-offs to increase the performance and/or efficiency of certain operations at the expense of others.
If we just look at the core architectures themselves across a wide set of content types then both architectures look pretty efficient and scalable, yet it’s well known that typically desktop/discrete GPUs use IMR, while mobile/embedded GPUs use TBR.
In order to better understand the trade-offs made by the two approaches we first need to look at the way how the two architectures access/exchange data throughout the pipeline.
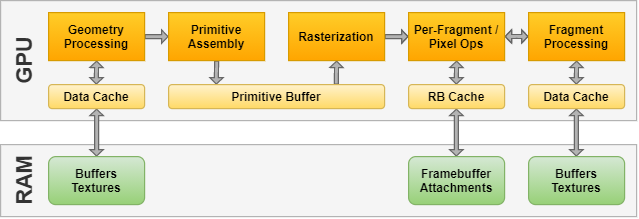
In case of IMR GPUs all application provided data is accessed through different types of caches (for more details read our earlier article on caches). Note that framebuffer attachments are accessed through the RB cache which consists of a set of color- and depth/stencil caches private to each ROP/RB (raster operation unit or render backend) of the GPU.
The entire pipeline is ran in a single phase, as discussed earlier, that is enabled by the on-chip primitive buffer that allows the fixed-function primitive assembly stage to push primitive data to the rasterizer.

In contrast, TBR GPUs write the primitive data off-chip into per-tile primitive bins which then are consumed by the subsequent per-tile operations issued in the second phase of the pipeline.
However, as the back-end stages of the TBR GPU operate on a per-tile basis, all framebuffer data, including color, depth, and stencil data, is loaded and remains resident in the on-chip tile memory until all primitives overlapping the tile are completely processed, thus all fragment processing operations, including the fragment shader and the fixed-function per-fragment operations, can read and write these data without ever going off-chip.
Shader reads/writes go through a standard GPU shader data cache hierarchy on both IMR and TBR GPUs.
As the amount of memory traffic is often the main bottleneck of GPU workloads both from performance and energy efficiency perspective, it follows that the better suited GPU architecture for any given workload is the one that requires less external memory bandwidth. More specifically, how the additional memory traffic on TBR GPUs incurred by writing the primitive data to off-chip per-tile primitive bins compare to the recurring memory traffic to/from the framebuffer attachments on IMR GPUs, and how both compare overall to the rest of the memory traffic generated by index and vertex buffer loads, texture reads, or other shader read/write operations.
Taking the simplest practical example, we’re talking about 10 bytes per vertex (16-bit integer framebuffer-space X, Y, and Z, plus 2x 16-bit floating point texture coordinates), at best 10 bytes per triangle (if all triangle vertices are shared with neighboring ones), while at the framebuffer side we’re talking about 6 bytes per pixel (32-bit LDR or 10-bit HDR color buffer, and 16-bit depth buffer), and these per-vertex and per-pixel sizes need to be taken into account, together with the primitive to pixel ratio, in order to estimate which GPU architecture type could be more efficient for a specific workload.
However, the equation is not that simple, as even TBR GPUs typically need to load and/or store each touched tile once (load can be avoided if the framebuffer contents are discarded or cleared before rendering while stores may be avoidable in a few specific scenarios as well), thus TBR GPUs need some level of overdraw to actually be able to amortize the cost of tile load/store. In addition, the information about which primitive overlaps with which tile needs additional storage and thus bandwidth in the per-tile primitive bin.
On the IMR side, it’s also important to consider the efficiency of the RB cache, because as long as multiple subsequent primitives get rasterized on a given ROP unit in the same framebuffer area then the RB cache can similarly amortize the cost of framebuffer reads/writes as the on-chip tile memory on TBR GPUs. In fact, the larger the GPU, and thus the higher the number of ROP units, it’s more likely for framebuffer accesses hitting in the RB cache.
Furthermore, modern TBR GPU implementations use aggressive lossless compression schemes for both the per-tile primitive bin storage and the off-chip storage of framebuffer attachments, that further skews the naive figures. Though that’s nothing new to IMR GPUs either, as modern implementations also employ lossless framebuffer attachment compression algorithms to save bandwidth.
Another technique available to TBR GPUs to reduce the bandwidth requirements of the per-tile primitive bins, often referred to as vertex shader splitting or deferred attribute shading, takes advantage of the fact that the binning stage only depends on the position of vertices. In such a scheme the geometry processing done in the first phase of the tile-based rendering only executes the part of the geometry processing stages (e.g. vertex shader) that are needed to determine the framebuffer-space position of the vertices (and possibly clip distances or other clipping/culling related data), as that’s the only information needed to decide which per-tile bin the primitive needs to be emitted to. In this case only index data (with or without position data) needs to be written to the per-tile primitive bins, the rest of the workload determining per-vertex and per-primitive outputs is instead performed in the second phase.
In the simplest case this may simply mean that the vertex shader work is moved into the fragment shader (similar to how the visibility buffer algorithm works), but more sophisticated implementations may employ a separate geometry processing stage (or stages) executed on the primitives in the per-tile bin. While this approach may potentially save a significant amount of external memory bandwidth in case of shaders using many interpolants, it usually results in redundant processing of the same vertices across the individual tiles, and the vertex buffer access pattern may be less cache-friendly due to gaps between the data of the subset of primitives overlapping the tile in question.
In order to allow better vertex buffer access performance on such hardware implementations it is advised to keep position-affecting vertex attributes in separate buffers from the rest, even if otherwise using an interleaved scheme within the vertex buffers. In fact, it’s generally good to follow this practice, as geometry-only passes like a depth pre-pass and shadow map generation passes can also benefit from it.
The possibility of using late attribute shading is not exclusive to TBR GPUs though as IMR GPUs may similarly benefit (or not). Reducing the amount of per-primitive data transferred from the front-end stages to the back-end stages, and delaying geometry processing workload after culling can be a performance win on any architecture. However, once again, whether the benefits of this approach outweight its drawbacks is highly dependent on the particular workload at hand.
Nonetheless, despite many parameters being at play, it’s a good rule of thumb that the higher the geometry complexity the more likely IMR GPUs will outperform their tile-based counterparts. Thus it comes as no surprise that despite mobile devices being able to drive rendering at very high resolutions with pretty pixel effects, geometric detail is usually significantly lower compared to similar renderings encountered on desktop, and features like tessellation that significantly increase the number of primitives to be rasterized continue to remain practical primarily only on desktop systems.
It’s also worth noting here that if the external memory traffic is dominated by fragment shader memory accesses, e.g. due to complex materials needing many high-resolution textures as input that is quite common in modern workloads, the differences between the two architectures diminish, even if we acknowledge that TBR GPUs may experience better spacial locality of memory accesses and thus may employ more sophisticated optimizations in order to accelerate these accesses, thanks to the stricter processing order inherent from tile-based rasterization.
Use Cases
Instead of trying answer the impossible and declare a winner here, let’s take a look at a couple of use cases and see how the two architectures tackle these problems, which can both give an idea of where each one shines and can lead to a better understanding of their behavior and rationale behind their design.
Hidden Surface Removal
During the rendering of a typical 3D scene it’s pretty much inevitable to have certain level of overdraw, and spending time on processing fragments/pixels of primitives that will later be covered by subsequent primitives in front of those can have a great impact on overall performance and efficiency.
IMR GPUs tackle this problem by relying on depth test to reject hidden pixels as early as possible. This enables even the most naive implementation to avoid having to generate framebuffer read/write traffic, but modern GPUs go well beyond that.
First, in most cases depth testing (and depth writes as well) can execute as part of the early per-fragment operations thus fragment shading can be avoided all together for hidden surfaces. A few exceptions to these are fragment shaders modifying the fragment depth value or discarding the fragment, which both delay depth writes to happen in the late per-fragment operations (as the depth value to write may change or shouldn’t be done in the first place), and if the fragment shader modifies the fragment depth in a way that could cause false negatives during early depth testing (i.e. fragment would fail depth testing before the fragment shader but would pass it after it) then the entire depth test needs to be delayed and fragment shader cost cannot be avoided even for fragments that end up being part of hidden surface in the end.

It’s worth noting though that even fragment shaders modifying the fragment depth may benefit from early depth testing if the modification doesn’t affect the depth test results, although this requires the application developers to explicitly declare their intent on how they plan to alter the fragment depth in the shader (see conservative depth).
In addition to early testing, IMR GPUs use Hi-Z (hierarchical depth) buffers and special depth-specific compression schemes that allow rejecting large groups of fragments (entire “tiles”) immediately, before even doing fine-grained rasterization. Discussing the details of this, however, is beyond the scope of this article.
Regardless of the individual optimizations in the hardware, taking advantage of this type of hidden surface removal always relies on the presence of a depth buffer and it’s best taken advantage of if the geometry is submitted to the GPU in front-to-back order. While the latter is fairly straightforward to achieve at the granularity of individual draw calls (although in case of overlapping geometry some overdraw may happen anyway), it usually cannot be ensured for primitives within a single draw call, in fact early depth test efficiency will often depend on the orientation of the geometry with respect to the view point.
Switching to TBR GPUs, avoiding framebuffer read/write traffic is less of an issue due to the data being in the fast on-chip tile memory, but avoiding unnecessary fragment shader invocations is just as important (if not more important) due to the external memory traffic they generate to read and interpolate incoming varyings/attributes (texture coordinates, normals, etc.) and fetch texture data.
Early depth testing and related optimizations found on IMR GPUs can be similarly employed by TBR GPUs, although some of the more sophisticated techniques may make less sense on them (at least in their traditional form). Nonetheless, they have other tools at their disposal for effective hidden surface removal due to all the geometry affecting the pixels of the tile in question being available at the time rasterization starts.
Before focusing on the back-end stages of the pipeline, it already can be noted that the primitive binning stage may be able to employ a similar technique to Hi-Z to avoid having to emit primitives to a tile’s bin if a previously emitted primitive is guaranteed to occlude it due to depth testing later on. Such an approach wouldn’t just avoid having to perform unnecessary fragment shading on the primitive, but can also save memory bandwidth consumed by the per-tile primitive bin writes/reads.
As part of primitive binning or during rasterization, TBR GPUs may also be able to partially or fully sort primitives front-to-back potentially achieving better hidden surface removal than their immediate-mode counterparts. Some TBR GPUs go even further than that and perform perfect per-pixel hidden surface removal and thus can guarantee that every single pixel gets shaded exactly once throughout the whole subpass. This can be achieved even in the absence of a depth buffer which comes handy in other use cases as we’ll see later.
Of course, these techniques may fall short in the presence of fragment shader discard, fragment shader depth modification, blending, and other scenarios that don’t satisfy the prerequisites of applying the corresponding optimitization, as we’ve seen in case of IMR GPUs.
2D Compositing
While we all appreciate our GPUs primarily for the beautiful 3D images they are able to produce, we have to admit that the most common workload we give to them in our daily use of computers is 2D composition, let that be the desktop UI composition itself or the compositing done to present web content in a browser.
In case of IMR GPUs there aren’t a whole lot of features helping 2D compositing use cases in particular. While depth testing and front-to-back rendering can be used for 2D compositing as well, it requires opaque-only geometry, and the often cheap fragment processing used by compositors rarely justify using a depth buffer. Thus basic graphics based 2D compositing is usually simply done using back-to-front rendering and using blending where applicable with appropriate hidden surface removal happening in software, using scissors and discard rectangles, potentially using the stencil buffer for complex cases, or with combinations of those.
In contrast, it seems like 2D compositing cases play to the streights of TBR GPUs due to the low geometry-to-pixel ratio and guaranteed on-chip blending. In fact this partly explains why tile-based architectures are favored in low-power and energy-constrained environments.
Talking about blending, IMR GPUs use dedicated fixed-function hardware for the purpose. Beyond being responsible for applying the appropriate blend composition itself, this component also has to make sure that pixels are blended on top of each other according to the incoming primitive order. This isn’t trivial when you can have shaders processing the fragments of different primitives that may overlap in framebuffer space scattered across the shader cores.
TBR GPUs don’t really have this problem, as they process all primitives covering a particular tile at the “same place”, seemingly in order (disregarding any potential reordering done for optimization purposes as explained earlier). This also enables typical TBR GPUs to allow fragment shaders to directly read or write their corresponding framebuffer pixels, opening the door for programmable blending and other compositing tricks unavailable to their IMR counterparts. In fact it’s not uncommon for the standard graphics API blending to be implemented on TBR GPUs through the driver patching the application provided fragment shader with blending code.
To be fair, similar benefits can be achieved using a compute shader on an IMR GPU mimicking tile-based composition, although while the on-chip tile memory contents are preserved when switching shaders on a TBR GPU the same isn’t true about data in shared memory across compute shader dispatches.
Loosely speaking, post-processing effects applied on top of a 3D scene also fall into this workload category, it’s thus no surprise that modern desktop applications usually use compute shaders to implement them.
Multisampling
Multisampled rendering enables faster antialiasing with similar quality to naive supersampling by only performing rasterization and certain per-fragment operations at a higher rate while continuing to do fragment shading only once per fragment/pixel. There are certain controls to alter that, potentially going all the way to full supersampling (shading each sample within a pixel individually), but the highest performance gains over supersampling are achieved in the basic case.
The behavior of multisampled rasterization is pretty much standardized, yet hardware implementation is quite different on IMR and TBR GPUs.
Multisampled framebuffer attachments have to be able to store a unique value for each sample in the edge case, however, it’s quite common for all samples to have the same color value (e.g. all opaque pixels lying entirely inside the primitive). IMR GPUs usually take advantage of this and instead of storing the same color value for each covered sample individually, they only store it once and add special metadata to the framebuffer attachment that tells which sample within the pixel has this particular stored value. This can reduce the consumed memory bandwidth considerably.
Although similar compression techniques can also be employed on TBR GPUs to use less bandwidth when loading/storing framebuffer attachment tiles, such optimizations are less interesting while the data is in the on-chip tile memory. TBR implementations instead go one step further and try to avoid storing multisampled images in memory all together when possible.

Note that multisampled data only exists on-chip.
In most cases image data lives in a multisampled format only temporarily, as after the frame is rendered the multisampled framebuffer attachments get resolved into single-sampled counterparts that are directly presentable to the screen. In the ideal case this can be leveraged by TBR GPUs to the extent that multisampled data only ever has to live in on-chip tile memory. In such a setup the multisampled framebuffer attachments never get loaded from or stored to memory, and thus don’t even consume external memory (see transient attachments), they only exist for the duration of the multisampled rendering and once the tile is completely rendered then the tile store operation will simply resolves the multisampled data on-chip into a single-sampled image in memory. This can save tremendous amount of memory bandwidth but only if the multisampled data doesn’t need to be preserved across render passes/frames.
Deferred rendering
There’s a long-standing myth (that luckily slowly disappears) that deferred rendering techniques are not suitable for TBR GPUs. The origins of this myth is probably poor performance observed on naive ports of deferred rendering applications to these platforms.
Ironically, the opposite is true if both the geometry pass and the deferred pass is part of the same render pass, as TBR GPUs don’t need to actually consume any external memory bandwidth for writing out and then reading (typically multiple times) the G-Buffer contents, that is usually the main bottleneck of such renderers. Instead, for each tile, the geometry pass will write G-Buffer data into the on-chip tile memory that is then later consumed by the deferred pass(es) and may never actually need to leave the GPU die. Actual mileage may vary though, as we will soon see.

Note that G-Buffer data only exists on-chip.
Shadow and Reflection Maps
There are many situations when the outputs of a rendering pass need to be mapped one way or another to some geometry, i.e. framebuffer attachments are reused as textures. Shadow map or reflection map rendering are perfect examples.
While IMR GPUs don’t particularly “like” these types of workloads, especially if the results of the rendering are immediately needed in the next subpass, and is often the cause of pipeline bubbles, they handle them just as well as any other type of workload. In fact, shadow map rendering often doesn’t require any fragment processing (except for partially transparent primitives, etc.), thus populating the depth attachment can be performed extremely fast by the fixed-function ROP units.
The same isn’t true for TBR GPUs, as even depth-only rendering requires the geometry data to be written out to memory and consumed by the rasterizer. However, the larger issue is the fact that the produced framebuffer data needs to be flushed from the on-chip tile memory, storing the data to memory, before the render pass that would like to map that image onto some geometry can start, practically eliminating many benefits of tile-based rendering.
Besides that, generating a shadow or reflection map requires pushing the scene geometry (even if just partially) down the graphics pipeline once more for each map, further stressing the main bottleneck of tile-based architectures. This is why we usually see less effects depending on these types of render-to-texture scenarios in applications primarily targeting TBR GPUs.
Other Considerations
Except the last use case presented, the examples above mostly showcased benefits of tile-based architectures over IMRs, the only drawback seeming to be the additional cost of having to write processed geometry back to memory before rasterization is started. However, this seemingly innocent trade-off has a lot of implications.
First, we have to note that besides the obvious memory bandwidth cost of going off-chip with geometry data that usually makes highly detailed geometry (even if tessellated within the graphics pipeline) impractical on TBR GPUs, there is also the question of how much memory this transient buffer needs.
Practically TBR GPU drivers need to determine how much geometry storage will be necessary during the entire render pass. This is fairly trivial for simple cases when the final post-transform primitive count matches the incoming count, or is less than that (e.g. due to culling), it simply needs book-keeping primitive/vertex counts of draw calls and delaying their submissions until data is collected from the entire render pass and appropriate primitive bin storage is reserved. However, that’s not always an option as in-pipeline geometry amplification (e.g. in case of tessellation or geometry shading) or indirect draws may break the correlation between input and output primitive count in ways that cannot be predicted.
In case the determined primitive bin storage size exceeds practical limits, or cannot be estimated, driver implementations will be forced to split the rendering workload into multiple render passes, potentially eliminating the advantages of tile-based rendering. This can happen even in Vulkan, despite having explicit render pass constructs at the API level, as a single render pass object can be turned into multiple render passes internally by the driver, if necessary, let alone traditional APIs where render pass boundaries are determined entirely by the driver often involving complex guess-work leading to unpredictable performance cliffs from the developer’s perspective.
Besides the primitive bin storage limitations, there are many other circumstances where render passes need to be split. As an example, a split may be necessary due to too many or too big (in terms of bytes-per-pixel) framebuffer attachments being used, or needed to be preserved in a subpass. Even if such cases aren’t handled by doing a full render pass split, they may result in needing to perform in-render-pass partial tile stores and reloads.
Other examples include workloads that contain feedback loops like transform feedback, occlusion queries (even indirect draws and render-to-texture scenarios can be included this category), especially when they contain back-end to front-end dependencies. Such feedback loops can have significant overheads on IMR GPUs as well, but not nearly as devastating as on their TBR counterparts.
Thus, while TBR architectures offer many potential benefits, they are more content sensitive and require careful attention from software developers to hit their sweet spot, while IMR architectures typically “work just fine” (though it should go without saying that efficient API usage makes a huge difference on both architectures, nonetheless).
Hybrid Architectures
Not all GPUs fall strictly in the IMR or TBR category, in fact many architectures employ some hybrid approach. The simplest hybrid architectures are GPUs that are capable of operating both in IMR and TBR mode thus allowing the underlying driver to use the best mode for the particular workload at hand.
Another class of hybrid architecture is one that is often referred to as tile-based immediate-mode rendering. As dissected in this article, this hybrid architecture is used since NVIDIA’s Maxwell GPUs. Does that mean that this architecture is like a TBR one, or that it shares all benefits of both worlds? Well, not really…
What the article and the video fails to show is what happens when you increase the primitive count. Guillemot’s test application doesn’t support large primitive counts, but the effect is already visible if we crank up both the primitive and attribute count. After a certain threshold it can be noted that not all primitives are rasterized within a tile before the GPU starts rasterizing the next tile, thus we’re clearly not talking about a traditional TBR architecture.
To understand what is happening here, we have to look at how rasterization workload is typically distributed across the multiple ROP units present on discrete GPUs. Loosely speaking, IMR GPUs also sort of work in a per-tile fashion in the sense that workload is usually sent to specific ROP units based on their framebuffer-space location to maximize RB cache hit rates. If the ROP unit count is sufficiently large for no two tile being served by the same unit then practically we can achieve similar framebuffer access performance like TBR GPUs, although obviously that’s rarely ever the case. That means the ROP units need to “context-switch” between tiles through the course of rendering the frame, resulting in decreased RB cache hit rates.
Thus what likely happens here isn’t tile-based rendering in its “standard” form, but rather on-chip buffering of incoming primitives and intelligently dispatching them to individual ROP units in an order that depletes all buffered primitives corresponding to a specific tile handled by a particular ROP unit before sending other buffered primitives that would require the ROP unit to switch to another tile.
While this approach can definitely achieve similar benefits to TBR GPUs in very low primitive count use cases like 2D composition, post-processing, decals, and certain particle effects, and should provide performance boost in general, it doesn’t offer the same whole-render-pass level benefits of TBR architectures, like the possibility of pixel-perfect hidden surface removal, on-chip multisampling, or on-chip deferred rendering, as the tile-based rasterization only happens across a small window of primitives (depending on how many of them fit in the on-chip primitive buffer) while TBRs use large off-chip buffers for the same purpose.
Conclusion
We presented the two most prevalent GPU architecture type, the immediate-mode rendering (IMR) architecture using a traditional implementation of the rendering pipeline, and the tile-based rendering (TBR) architecture that takes a different approach to achieve the same goals.
Along the discussion we also explored a set of use cases that highlight key strengths and weaknesses of each.
While both architectures have their merits and each clearly has an advantage over the other in specific scenarios, there is no free lunch in the context of GPU architectures, just as nowhere else in the world of algorithm optimization, as both architectures make specific compromises to sacrifice performance in one part of the pipeline in order to gain performance elsewhere.
Thus it is doubtful whether the development of all GPUs will converge towards either, instead, each architecture will continue to be used in systems that get the most benefits from the specific trade-offs characterizing it.
It is not unlikely though that we will see more hybrid architectures on systems where the additional hardware cost is justified by being able to handle a wider range of content efficiently, and that graphics APIs will continue to introduce explicit mechanisms, like Vulkan’s render pass API, to enable more direct and effective use of quirkier GPU features like the two-phase per-tile rendering, as these reduce the reliance on driver guess-work and thus lead to more predictable rendering performance.